Матричный параллельный процессор для вычисления преобразования адамара
Похожие патенты | МПК / Метки | Текст | Заявка | Код ссылки
Номер патента: 478306
Автор: Гречишников




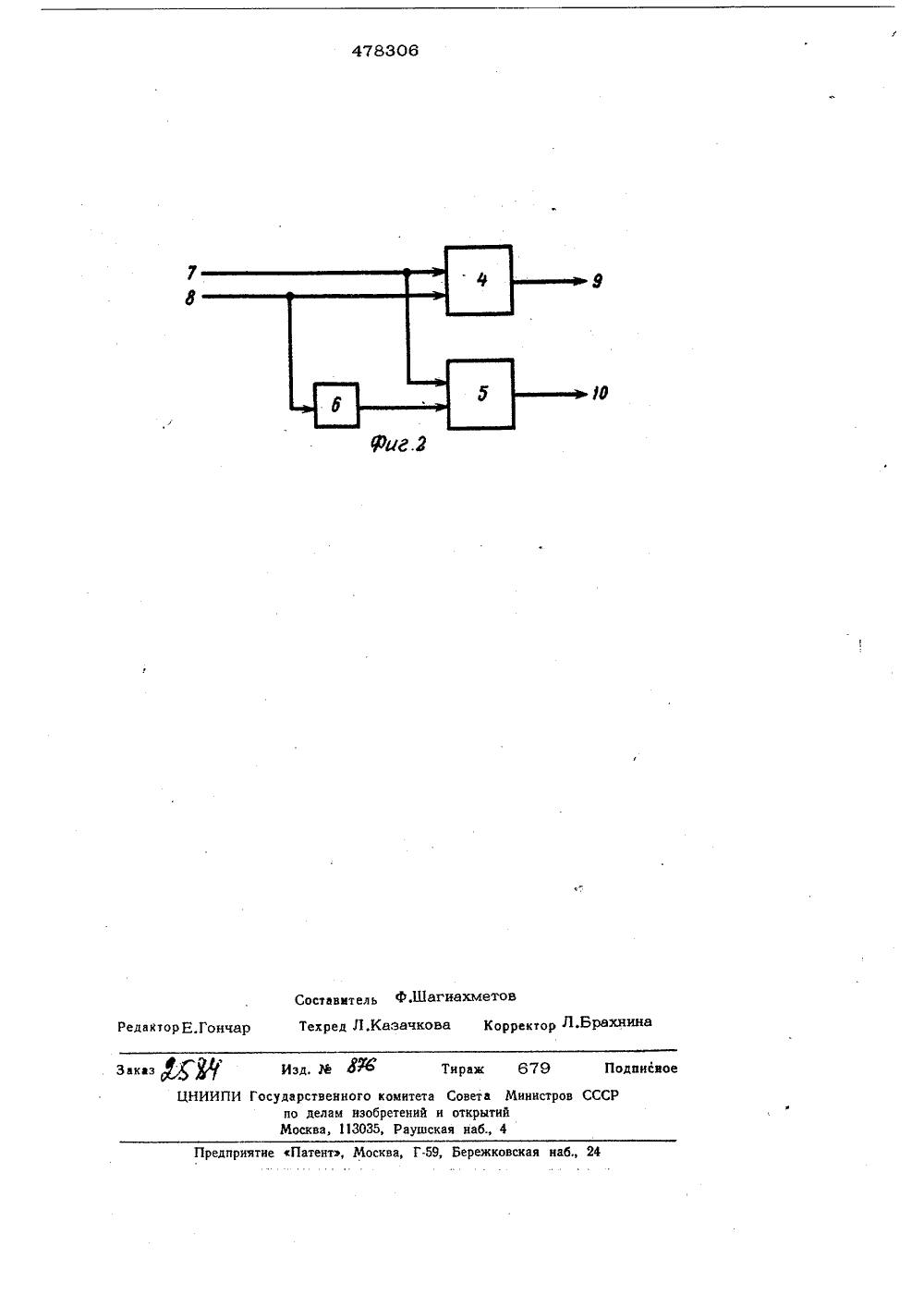
Текст
Оп ИСАНИЕ ИЗОБРЕТЕНИЯ К АВТОРСКОМУ СВИДЕТЕЛЬСТВУ Союз СоветскихСоциалистицеооаРеспублик(61) Дополнительное к авт, свид-ву(22) Заявлено 25,07.73 (21) 1948110/18-24с присоединением заявки 51) М. Кл. 0061 9/00 0 06 Й 15/20 Гввудвротвевмв комвтвт Ввввтв Маеотров ССР вв делам взобретеей м открытие(71) Заявитель 4) МАТРИЧНЫЙ ПАРАЛЛЕЛЬНЫЙ ПРОЦЕССОР ДЛЯВЫЧИСЛЕНИЯ ПРЕОБРАЗОВАНИЯ АДАМАРАИзобретение относится к вычислительной технике и может быть использовано в системах обработки изображений, для цифровой фильтрации и в системах связи.Известен матричный параллельный про- а цессор для вычисления преобразования Адамара, содержащий в узлах матрипы вычислительные блоки, выполненные в виде сумматоров, входы каждого нз которых соединены с входами вычислительного блока, 10 а первый выход каждого вычислительного блока соединен с выходом соответствующего сумматора. Невысокое быстродействие известного процесса обусловлено затратами времени на хранение промежуточ ных результатов вычислений до окончания операции,Бель изобретения - повышение быстродействия матричного параллельного процессора, 20Достигается это тем, что каждый вычислительный блок содержит инвертор и дополнительный сумматор, выход которого соединен со вторым выходом вычислительногоблока, один вход которого соединен с пер вым входом дополнительного сумматоранепосредственно, а другой вход через инвертор соединен со вторым входом дополнительного сумматора, причем входы первого вычислительного блока второго итретьего столбцов матрицы соединены спервыми выходами первого и второго вычислительных блоков первого и второго,столбцов матрицы соответственно, входывторого вычислительного блока второго итретьего столбцов матрицы соединены спервыми выходамн третьего и четвертоговычислительных блоков первого и второгостолбцов матрицы соответственно, входытретьего вычислительного блока второго итретьего столбцов матрицы соединены свторыми выходами первого и второго блоков первого и второго столбцов матрицысоответственно, входы четвертого вычислительного блока второго и третьего столбцов матрицы соединенысо вторыми выходами третьего и четиеотого емчиолитель .ных блоков первого и второго столбцов матрицы соответственно, а входы вычислительных блоков первого столбца и выходы478306 В 2 В 2 В+ 0,5 СП 0,010011 01,110011 01 0,0 00,110011 01,10011 10,00011 10 О 0100 0,00101 О 001010 0,0010101 0,00101000 0,0010011 00,0001100,1011 00,0011 00,1011 01,111 10,01 01,0 00,1 01,011 00,11101,11 00, 01 00,1 00,0 00,0 Таблица 2. вычислительных блоков третьего столбца матрицы соединены с входами и выходами,процессора непосредственно.На фиг, 1 представлена блок-схема:.процессора, на фиг, 2 схема вычисли,тельного блока.Матричный параллельный процессор со,держит вычислительные блоки 1, объедипенные в три столбца. 1 Ьфрами 2 и 3 обоз"начены соответственно входы и выходы процессора.Вычислительный блок 1 содержит сумма;торы " 4, .5 и инвертор 6. Цифрами 7,8 и 9, 10 рбозначены входы и выходы вычис-. лительного блока соответственно,Информация поступает в процессор, бу,дучи закодированной в виде степенных приДекодирование представляет собой алгебраическое сложение количественныхэквивалентов (весов) степенных приращений (см. последний,;столбец табл. 1). Как видим выполнение операции сложе., ния возможно только при отсутствии переносов на один разряд вперед, т. е. при отсутствии комбинаций степенных прираще;ний вида 10.10 и 00.00. Это условие вы;полняется всегда в силу существования ряда теорем. Пример сложения закодированного ранеечисла А = 0,0010011 (СП = 01.10.00.1 101.10.01.00) и чйсла А = 0,0010101:ращений (СП). Кодирование производят последующему алгоритму:Масштабирование информации в пределах от 0 до 1.Сложение с числом 0,5,Умножение на 2,Сложение с числом 0,5.Первые два двоичных разряда, стоящие1 слева от запятойявляются очередным сте-.,пенным приращением.В табл. 1 приведен пример кодирования.,числа А=О,0010011 в виде степенных при 1 ращений, тогда В - (А + 0,5) 10 -= (0,1010011) где В - кодируемоеФчисло, а- номер шага кодирования,Таблица 1.СП СП СП А + А 01 01 10 0,110 10 00 О 01 00 00 01 0,01001 10 10 0,0101 10 00 01 0,01010 01 10 01 0,01010000 00 01 0,0101 ООО Сложение производится по мере поступления прйращений, в приведенном примере5 478Фсверху вниз, т. е. от старших приращений к младшим.Каждый вычислительный блок 1 матричного параллельного процессора реализует выражения:А;+1=А,+ И; (1) 8+ =А -В 1 1 (2) где 1, - номер столбца матричного параллельного процессора, А В - операнды, поступающие на входы с 7 и 8 вычислительного блока 1 соответственно,А + 1, В.+ 1 - результаты вычислений, поСступающие на выходы 9 и 10 вычислительного блока 1 матричного параллельно-, го процессора соответственно.Вычислительные бдоки 1 соединены между собой в соответствии с графом, описы.г вающнм быстрое преобразование Адамара.Количество входов матричного параллельного процессора всегда кратно степени двойки. Тогда количество столбцов процессора будет равно величине показателя степени, а число строк - числу входов деленному пополам. Каждый вычислительный блок 1 обрабатывает информацию последовательно, начиная со старших разрядов. Вычислительный блок 1 реализует формулы (1) и (2), причем сумматор 4- формулу (1), а сумматор 5 - формулу (2). Инвертор 6 необходим для умножения числаВ на -1.306 6 Ю 15 20 30 35 с формулами (1) и (2). Степенные приращения результата выдаются . нз вычислительного блока 1, а на вход одновременно с выдачей поступают следующие парыприращений. Следует отметить, что каждыйсумматор, входящий в состав блока 1 матричного параллельного процессора, задерживает информацию.на один такт, что спедуетиз указанного выше алгоритма сложениядвух чисел, представленных в виде степенных приращений. Очевидно, что вычислительный блок 1 матричного параллельного процессора в целом также задерживает информацию на один такт.Оценим быстродействие матричного параллельного процессора. Оно определяетсязадержкой всех вычислительных блоков 1,т. е, задержкой в наиболее короткцй последовательной цепи, составленной из вычислительных блоков 1. В данном случае длина цепи равна количествустолбцов мат-,ричного параллельного процессора, которое можно вычислить по формуле =ОН,Тогда время, необходимое для обработкивсего исходного массиве чисел (в тактах)Т=о Н + Игде Н - количество входов матричного параллельного процессора, равноеколичеству чисел в исходном об- .рабатываемом массиве, а Мчисло старших разрядов результата,обеспечивающее необходимую точность вы-числений.Если Н = 1024, длительность одноготакта равна 1 мксек, а М=10, то Т=20мксек, что в 800 раз быстрее, чем у известного процессора,Работа матричного параллельного процессора происходит следующим образом, На входы 2 поступает последовательно информация, закодированная в виде степенных приращений. Обработанные в первом столбце матричного параллельного процессора старшие разряды результата поступают для дальнейшей обработки во второй столбец, оттуда - в третий и т. д, В то время, как с выходов 3 происходит выдача старших разрядов окончательного результата преобразования Адамара, на входы 2 еще продолжают поступать младшие разряды исходного массива чисел. Приняв с выходов 3 достаточное для обеспечения необходимой точности количество старших разрядов результата, процесс вычислений можно остановить. Легко видеть, что работа вычислительного блока 1 матричного параллельно"- го процессора заключается в приеме очередных степенных приращений операндов и сложении (вычитанни) их в соответствии 45 50 55 60 Предмет изобретения Матричный параллельный процессор для вычисления преобразования Адамара, содержащий в узлах матрицы вычислительные блоки, выполненные в виде сумматоров, входы каждого из которых соединены с входами вычислительного блока, а первый выход каждого вычислительного блока соединен с выходом соответствующего сумматора, отл и ч а ю щ н й с я тем, что, с цег 1 ью повышения быстродействия, каждый вычислительный блок содержит инвертор и дополнительный сумматор, выход которого соединен со вторым выходом вычислительного блока, один вход которого соединен с первым входом дополнительного сумматора. непосредственно, а другой вход через ин вертор соединен со вторым входом дополнительного сумматора, причем входы первого вычислительного блока второго и треть,его столбцов матрицы соединеныс первымивыходами первого и второго вычислительныхблоков первого и второго столбцов матрицы соответственно, входы второго вычислительного блока второго и третьего столбцов матрицы соединены с первыми выходами третьего и четвертого вычислительных блоков первого и второго столбцовматрицы соответственно, входы третьего 10вычислительного блока второго и третьего столбцов матрицы соединены со вторыми выходами первого и второго блоковпервого и второго столбцов матрицы соответственно, входы четвертого вычислительного блока второго и третьего столбцов,матрицы соединены со вторыми выходамитретьего и четвертого вычислительных:блоков первого и второго столбцов матри:цы соответственно, а входы вычислительных блоков первого столбца и выходы вычислительных блоков третьего столбцаматрицы соединены с входами и выходамипроцессора соответственно.478306 Составитель ф.йагиахметов Техред Л,Каэачкова Корректор Л.Б а едактор Е,Гонч Зака ЦНИИПИ Государственного комитета Совета Министров СССР по делам изобретений и открытий Москва, 113035, Раушская наб., 4 Предприятие Патент, Москва, Г.59, Бережковская наб., 2 Р Ф Изд, М 8 Тираж 679 Подписное
СмотретьЗаявка
1948110, 25.07.1973
ГРЕЧИШНИКОВ АНАТОЛИЙ ИВАНОВИЧ
МПК / Метки
МПК: G06F 17/16
Метки: адамара, вычисления, матричный, параллельный, преобразования, процессор
Опубликовано: 25.07.1975
Код ссылки
<a href="https://patents.su/5-478306-matrichnyjj-parallelnyjj-processor-dlya-vychisleniya-preobrazovaniya-adamara.html" target="_blank" rel="follow" title="База патентов СССР">Матричный параллельный процессор для вычисления преобразования адамара</a>
Устройство для диагностики блоков электронных вычислительных машин

Номер патента: 650080
Опубликовано: 28.02.1979
Авторы: Караханьян, Мкртумян
МПК: G06F 11/04
Метки: блоков, вычислительных, диагностики, машин, электронных
...разряды регистра 2 устанавливаются в 1. Вследствие того, что выходы регистра 2 образуют в этих позициях монтажное И с выходами проверяемого типового элемента замены, при опросе ьыходов регистра тестов в этих позициях будут значения выходов проверяемого типового элемента замены. Благодаря этому в устройстве отсутствует коммутатор, который в других стендах обеспечивает коммутацию входови выходов.Опрос выходов регистра 2 тестов осуществляется с помощью преобразователя 7 параллельного кода в последовательный, 650080информация с выхода которого поступает в регистр 3 обмена и далее в блок 5 сравнения, После установки проверяемого типового элемента замены в разъем устройства и запуска устройства данные с внешнего носителя тестовой...
Устройство для диагностики блоков электронных вычислительных машин

Номер патента: 746556
Опубликовано: 05.07.1980
Авторы: Караханьян, Мкртумян
МПК: G06F 11/277
Метки: блоков, вычислительных, диагностики, машин, электронных
...накопителя 1через регистр 2 поступают в регистр4, в результате на входе блока11 устанавливается необходимая тестовая последовательность, после чего согласно программе контроля из 15 накопителя 1 в регистре 5 устанавливается контрольный код ожидаемой навыходе регистра 4 информации. Анализ правильности состояния блока 11для данного тестового набора осуще- ;Щ ствляется в блоке 7, точнее,схемой сложения по модулю К.Для пояснения сущности процессаанализа результатов рассмотрим рабо"ту схемы, приведенной на фиг.2,гдев схеме контроля использован сумматор 23. В момент времени "0",определяемый состоянием "О" счетчика20, на выходы преобразователей 18.118,п поступают значения битов О,в, 302 вщ(п)+1 регистра 4 а на выФходе преобразователя 22 -...
Вычислительное устройство и запоминающий масштабно суммирующий блок

Номер патента: 1043670
Опубликовано: 23.09.1983
Авторы: Заподовников, Самокиш
МПК: G06G 7/12
Метки: блок, вычислительное, запоминающий, масштабно, суммирующий
...коммутатора является выходом устройства, другие информационные входы-выходы перво 30 го коммутатора являются соответствующими входами устройства, управляющие входы первого и второго коммутаторов соединены с выходом генератора тактовых импульсов, введены блок определения знака, блок памяти, блок вычисления знака результирующего сигна.- ла, формирователь тактовых импульсов режимов суммирования, причем обратимый логарифмический преобразователь4 О выполнен двухполярным, вход-выход второго коммутатора соединен со входом блока определения знака, выход которого подключен к информационному входу блока вычисления знака результирующего сигнала и к первому входу45 формирователя та кто вых и мпул ь сов режимов суммирования, управляющие входы...
Процессор матричной вычислительной структуры для решения дифференциальных уравнений в частных производных
Номер патента: 1280385
Опубликовано: 30.12.1986
Авторы: Золотовский, Коробков
МПК: G06F 17/13
Метки: вычислительной, дифференциальных, матричной, производных, процессор, решения, структуры, уравнений, частных
...устранения дополнительной пересылки иэ регистра с регистр и обеспечения возможности дополнительной проверки на работоспособность каждого решающего блока. После обмена информацией между процессорами описанные операции повторяются до тех пор, пока процесс не сойдется во всех процессорах. Проверка организуется программно. Формула изобретения 11. Процессор матричной вычислительной структуры для решения дифференциальных уравнений в частньм производных, содержащий первый и второй решающие блоки первый регистр, информационный вьход первого решающего блока подключен к первому информационному входу второго решающего блока, информационный выход которого подключен к первому информационному входу первого решающего блока, с т л и ч а ю щ и й с я...
Устройство для анализа частоты использования блоков информации в вычислительных комплексах

Номер патента: 1793442
Опубликовано: 07.02.1993
Авторы: Буркин, Вдовиченко, Кишенский, Христенко
МПК: G06F 13/00
Метки: анализа, блоков, вычислительных, информации, использования, комплексах, частоты
...входом сумматора 35, второй вход которого подключен к установочному входу блока 5 (для всех блоков 5 этот вход задает код "единицы"), Выход блока 35 соединен с вторыми информационными входами всех блоков 36,Устройство работает следующим образом,В исходном состоянии все счетчики " групп 161-1 бз и все ячейки памяти блоковпамяти ЗЗ в блоках анализа 51-5 з обнулены, триггер 7 - также в нулевом состоянии, генератор 12 не формирует импульсов; счетчик 13 - также в нулевом состоянии.В режиме анализа на информационные входы 19 и 20 регистров 1 и 2 подаются соответственно код адреса блока информации, к которому поступает запрос, и код источника запроса (например, номер одного из процессоров, запрашивающих данный блок информации). Сигналом...
Предыдущий патент: Устройство умножения чисел
Следующий патент: Устройство для управления процессом
Случайный патент: Способ получения медного порошка в автоклаве